2 - Pourquoi visualiser l'apprentissage automatique ?
Les algorithmes d’apprentissage automatique diffèrent fondamentalement des algorithmes conventionnels. Peter Norvig, directeur de la recherche chez Google1, justifie ainsi le besoin de mieux comprendre l’apprentissage automatique.
“On the traditional software model, we have a programmer they create a bunch of rules, they write them down, they try to get all the rules right, it’s hard to do right because there’s complexity. In machine learning models, it’s not a programmer that writes the program, it’s a machine that writes the program and how does the machine know to write the program? Through data. You show it lots of examples, you give it a model that says “this is what I think the world is like” and then you tell the system : “arrange it so that in the future you’ll do things similar to the examples you saw in the past. And then, outcomes what’s mostly a black box. So you give examples in, what comes out is a program that will do the right thing. You’re not quite sure exactly how it works. But it’s a black box with a leed that’s open because we can peer inside it and one of the big challenges now is, how do you peer inside and how do you understand what’s been written by this machine.” 2
Ainsi, le développeur conçoit le cadre d’apprentissage et de fonctionnement pour l’algorithme mais il n’en implémente pas tous les aspects logiques. Il devient alors difficile de cartographier le fonctionnement de l’algorithme de manière précise comme précédemment avec l’algorithme d’Euclide. Hors, ces nouveaux algorithmes sont au coeurs des développements récents de nos sociétés.
Problème : des enjeux vitaux et omniprésents
Facebook est apparu en 2004, Youtube en 2005 et Twitter en 2006. Depuis 15 ans, des plateformes numériques diverses ont rencontré d’importants succès sociétaux et commerciaux. Elles sont les premières applications d’ampleur qui ont confronté le grand public à des algorithmes de classification et plus globalement d’apprentissage automatique. La figure suivante présente un pannel de plateformes numériques et leurs effets potentiels sur la conception de la démocratie, des goûts, des relations sociales, d’une vie professionnelle ou privée.
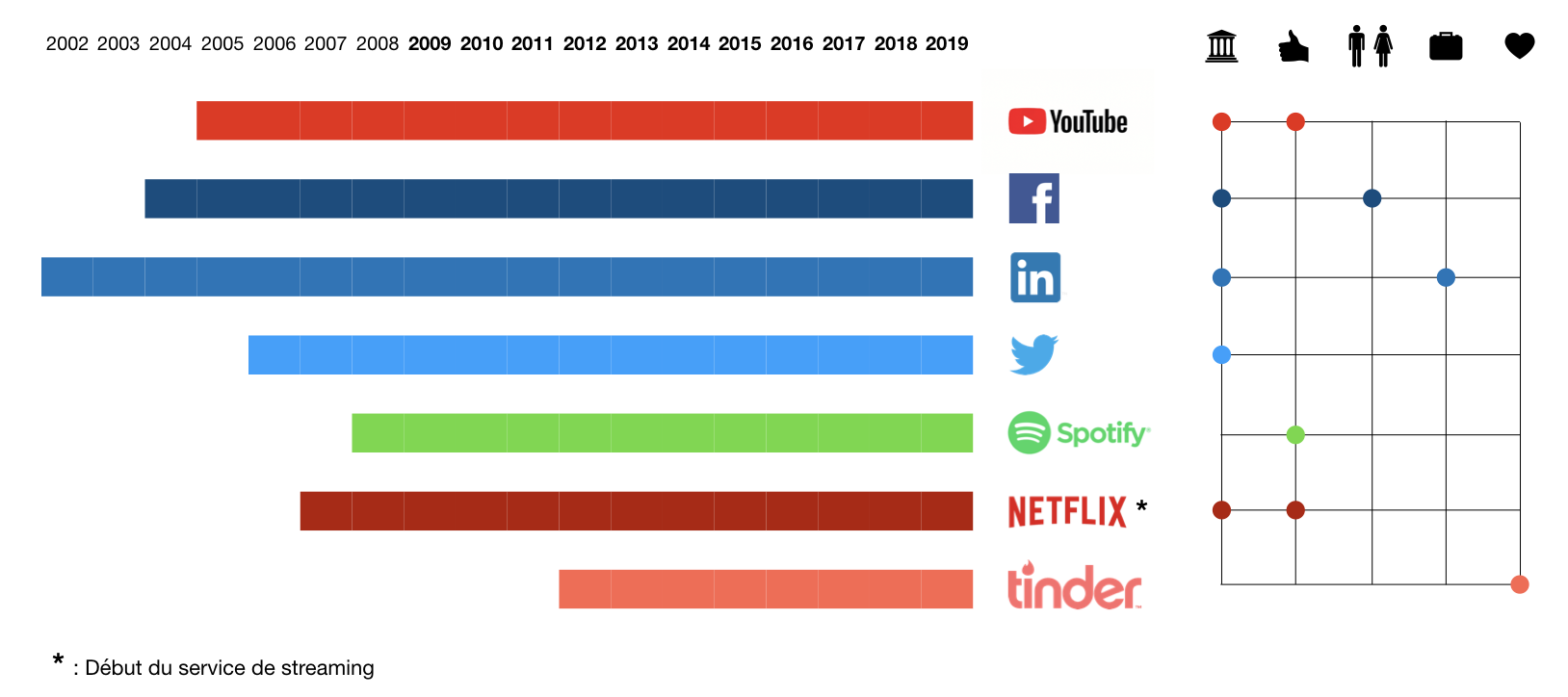
Figure 1 : Des outils numériques et leur influence.
L’omniprésence de ces plateformes peut par exemple nous interroger sur la manière dont des algorithmes d’apprentissage automatique accompagne le développement des personnes. Les critères suivants3 constituent ceux qui peuvent nous préoccuper sur les dix dernières années d’utilisation de plateformes.
- Équité et impartialité - Les algorithmes m’ayant orienté m’ont-ils enfermé dans une bulle ou possédaient-ils des biais ?
- Vie privée - Les entreprises ont elles mis en place des limites d’utilisation satisfaisantes de mes données ?
Les critères suivants3 sont ceux qui pourraient commencer à me préoccuper dans les dix prochaines années.
- Fiabilité, robustesse, causalité - Je monte à bord d’une voiture ou d’un avion autonome, je souhaite m’assurer que les algorithmes d’apprentissage automatique qui dirigent l’engin sont fiables et peuvent s’adapter à des perturbations inattendues.
- Utilisabitité et confiance - La système autonome me donne t-il les informations nécessaires pour que je puisse m’en servir correctement et pour que je lui fasse confiance ?
Ces questions sont légitimes mais personne ne peut individuellement forcer une organisation à expliquer comment leurs algorithmes d’apprentissage automatique fonctionnent. Une réponse à cela pourrait se trouver dans la loi.
Le droit à l’explication, une réponse ?
La RGPD (Règlement Général sur la Protection des Données) est entrée en vigueur en 2018. Elle donne un cadre à l’exploitation des données à caractère personnel. Les articles 13 et 14 concernent les informations à fournir lorsque des données personnelles sont collectées ou non auprès d’un individu. Ils évoquent dans les mêmes termes une information obligatoire à fournir, par l’organisation à l’individu concerné, afin de garantir “un traitement équitable et transparent” dans le cas d’une prise de décision automatisée :
“des informations utiles concernant la logique sous-jacente, ainsi que l’importance et les conséquences prévues de ce traitement pour la personne concernée.”4
Émerge donc l’idée qu’un droit à l’explication existe pour chaque individu dont les données sont utilisées en apprentissage automatique. Comme nous le verrons plus tard, la formulation de la RGPD n’est pas si explicite que cela, néanmoins cela montre qu’un besoin de transparence est maintenant en germe dans nos lois. Supposons donc que les craintes évoquées plus haut on été entendues par le régulateur et mises en forme. Nous serions alors en mesure d’exiger des créateurs d’algorithmes d’apprentissage automatique plus de transparence. C’est malheureusement là que le problème devient complexe.
Opacité de l’apprentissage automatique
Comme évoqué plus haut, les algorithmes d’apprentissage automatique ne consistent pas en une série de règles logiques immaginées par un programmeur au préalable, puis implémentées. Présenter leur architecture est donc un problème sérieux, c’est pourquoi nous admettons généralement que les algorithmes d’apprentissage automatique sont particulièrement opaques. Jenna Burrell, professeure à Berkeley, s’intéresse à l’interprétabilité des algorithmes d’apprentissage automatique. Elle distingue trois catégories d’opacité associées à ces algorithmes5.
- Opacité intentionnelle par discrétion : certains algorithmes d’apprentissage automatique peuvent avoir leur code protégé par leurs propriétaires. Ces derniers peuvent ainsi chercher à conserver un avantage compétitif ou assurer la performance de leur produit (ex : un filtre de spam ne sera pas efficace si les responsables de ces mêmes spams savent exactement comment vous vous en protégez). Ce type d’opacité est volontaire et peut se justifier. Si besoin le régulateur peut demander l’audit ou l’ouverture du code au public.
- Opacité technologique : les algorithmes d’apprentissage automatique sont implémentés dans des languages informatiques. Ces languages ne sont intelligibles que par un fragment de la population ce qui rend les algorithmes inaccessibles pour beaucoup. Par ailleurs, une grande latitude est laissée à tout développeur. Cela signifie qu’un même programme pour la machine pourra être rédigé d’une manière qui facilite ou empêche la lecture. Ce type d’opacité est malheureux mais est indépendant de l’algorithme. L’éducation à la bonne rédaction de code et l’enseignement de sa compréhension sont les seules armes à notre disposition.
- Opacité opérationnelle : les algorithmes d’apprentissage automatique reposent sur une intéraction entre des données et des règles de modélisation. Ce dernier type d’opacité est du à notre incapacité à comprendre la dynamique qui allie les données et les règles dans le processus d’apprentissage. C’est ce type d’opacité que nous nous proposons de traiter dans la suite de cette étude.
Il faudrait ainsi rendre interprétables les modèles. On peut définir ainsi l’interprétabilité :
“Ability to explain or to present in understanding terms to a human.”3
À noter par ailleurs avant d’aller plus loin qu’il existe des cas dans lesquels l’opacité n’est pas un problème. En effet, il est possible que nous n’ayons pas besoin d’expliquer le contenu et fonctionnement d’une boite noire. Un premier exemple consiste en des algorithmes dont les conséquences seraient faibles : les résultats innacceptables n’entraineraient alors pas de problèmes majeurs. Un autre cas pour lequel l’opacité n’est pas un problème est le cas d’une application où le système n’évolue pas et pourrait être testé en amont sur des millions de données. En traitant le système comme une boite noire, nous serions alors en mesure de prédire par l’expérience son fonctionnement.
Trois publics et quatre raisons pour lesquels visualiser
On peut distinguer trois publics de destinataires de la visualisation de l’apprentissage automatique.
- Architectes : développeurs de modèles
- Entraineur : utilisateurs de modèles
- Utilisateur final : grand public
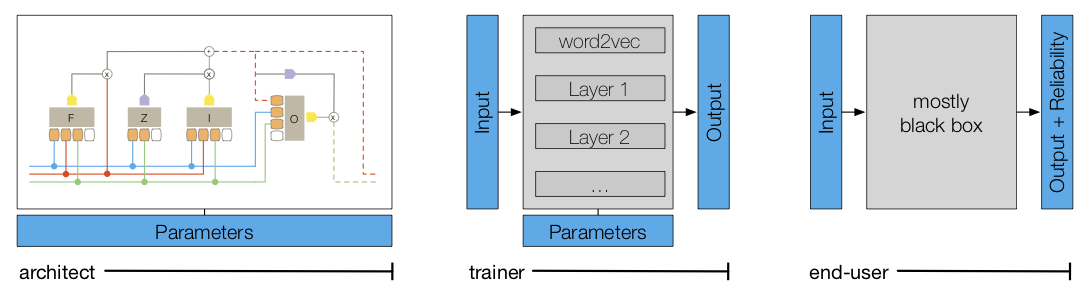
Figure 1 : Les destinataires de la visualisation du deep learning6
Nous pouvons par ailleurs distinguer quatre raisons de visualiser l’apprentissage automatique :7
- Interprétabilité : volonté d’explication
- Optimisation : débugger et améliorer
- Comparaison : afin de sélectionner des modèles
- Enseignement : faire comprendre l’apprentissage automatique à des étudiants
De part les enjeux sociétaux liés à leur utilisation ainsi que par leur opacité les algorithmes d’apprentissage automatique sont donc dignes d’étude. Par ailleurs, la variété des bénéficiaires et d’applications ajoute à l’intérêt de la tâche.
Partie 3 : Expliquer l’apprentissage automatique
Références
-
Google Research Site internet ↩
-
Peter Norvig, Conférence USI 2015, (3:10 - 4:10) ↩
-
Finale Doshi-Velez, Been Kim, Towards A Rigorous Science of Interpretable Machine Learning, 2017 ↩ ↩2 ↩3
-
Jenna Burrell, How the machine ‘thinks’: Understandingopacity in machine learning algorithms, 2016 ↩
-
Hendrik Strobelt, Sebastian Gehrmann, Hanspeter Pfister, and Alexander M. Rush, LSTMVis: A Tool for Visual Analysis of Hidden State Dynamics inRecurrent Neural Networks, 2017 ↩
-
Fred Hohman, Minsuk Kahng, Robert Pienta, Duen Horng Chau, Visual Analytics in Deep Learning:An Interrogative Survey for the Next Frontiers, 2018 ↩